Process Synchronization : 프로세스 동기화
= Concurrency Control
프로세스 동기화가 되기 위한 3가지 조건
Mutual Exclusion(상호 배제)
CS에 동시 접근이 안됨.
Progress
CS에 아무것도 없을 때 누군가는 접근해야 할 때 허용하게 하는것.
- Bounded Waiting
waiting time이 유한해야 한다는 말.
알고리즘 1
이 알고리즘에서는 turn이란 변수(Synchronization variable)을 사용하여 문제를 해결한다.
Process A, Process B가 있다고 가정하고 코드를 살펴보자.
A,B의 차이는 turn에 있음.
Process A(turn 값 = 0)
do {
while(turn != 0);
critical section
turn = 1;
remainder section
} while(1);
Process B(turn 값 = 1)
do {
while(turn != 1);
critical section
turn = 0;
remainder section
} while(1);이 조건은 첫번째 상호배제 조건은 충족하나 Progress를 만족시키지 못함.
반드시 A다음에 B 또는 B 다음에 A가 수행되도록 설계되어 있다.
A 또는 B가 둘 중 하나의 프로세스가 다른 프로세스에 비해 CS을 빈번하게 수행해야되는 프로세스일 경우, 해결되지 않을 것이다.
알고리즘 2
boolean flag = false 활용.
do {
flag[i] = true; // critical section에 들어가기 위해 true 값으로 바꾼다.
while(flag[j]); // 다른 프로세스를 확인한다.
critical section;
flag[i] = false; // critical section에서의 수행을 마치고 다시 false로 바꿔준다.
remainder section
} while(1);
마지막으로 알고리즘 3 생김
Peterson's Algorithm이라고 불리는 앞에 1,2 합쳐놓은것
do {
flag [i] = true;
turn = j; // 상대방 턴으로 바꿔둔다.
while(flag[j] && turn == j){ //
critical section
flag[i] = false;
remainder section
}
} while(1);둘 다 접근하려고 하는 경우에는 turn의 값으로 접근할 프로세스가 결정된다. 그렇지 않은 경우에는 flag값을 통해서 접근할 수 있다. 하지만 이 알고리즘에 문제가 없는 것은 아니다.
바로 Busy Waiting(= spin lock) 이 발생.
계속 CPU와 memory를 사용하면서 대기하는 상황인 것.
쓸데없이 while 속에서 무한 루프를 반복하면서 대기하고 있는 것은 비효율적인 방법.
그래서 Wait가 나타나긴함. 이 명령어는 대기가아니라 pause상태로 놓는것.
데커알고리즘와 피터슨 알고리즘 이해하기!!!
Peterson’s Algorithm for Mutual Exclusion | Set 1 (Basic C implementation)
Problem: Given 2 process i and j, you need to write a program that can guarantee mutual exclusion between the two without any additional hardware support.
Solution: There can be multiple ways to solve this problem, but most of them require additional hardware support. The simplest and the most popular way to do this is by using Peterson Algorithm for mutual Exclusion. It was developed by Peterson in 1981 though the initial work in this direction by done by Theodorus Jozef Dekker who came up with Dekker’s algorithm in 1960, which was later refined by Peterson and came to be known as Peterson’s Algorithm.
Basically, Peterson’s algorithm provides guaranteed mutual exclusion by using only the shared memory. It uses two ideas in the algorithm,
- Willingness to acquire lock.
- Turn to acquire lock.
Prerequisite : Multithreading in C
Explanation:
The idea is that first a thread expresses its desire to acquire lock and sets flag[self] = 1 and then gives the other thread a chance to acquire the lock. If the thread desires to acquire the lock, then, it gets the lock and then passes the chance to the 1st thread. If it does not desire to get the lock then the while loop breaks and the 1st thread gets the chance.
Implementation in C language
Output:
Thread Entered: 1
Thread Entered: 0
Actual Count: 2000000000 | Expected Count: 2000000000
The produced output is 2*109 where 109 is incremented by both threads.
This article is contributed by *Pinkesh Badjatiya *. If you like GeeksforGeeks and would like to contribute, you can also write an article using contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Peterson’s Algorithm for Mutual Exclusion | Set 2 (CPU Cycles and Memory Fence)
Problem: Given 2 process i and j, you need to write a program that can guarantee mutual exclusion between the two without any additional hardware support.
We strongly recommend to refer below basic solution discussed in previous article.
Peterson’s Algorithm for Mutual Exclusion | Set 1
We would be resolving 2 issues in the previous algorithm.
Wastage of CPU clock cycles
In layman terms, when a thread was waiting for its turn, it ended in a long while loop which tested the condition millions of times per second thus doing unnecessary computation. There is a better way to wait, and it is known as “yield”.
To understand what it does, we need to dig deep into how the Process scheduler works in Linux. The idea mentioned here is a simplified version of the scheduler, the actual implementation has lots of complications.
Consider the following example,
There are three processes, P1, P2 and P3. Process P3 is such that it has a while loop similar to the one in our code, doing not so useful computation, and it exists from the loop only when P2 finishes its execution. The scheduler puts all of them in a round robin queue. Now, say the clock speed of processor is 1000000/sec, and it allocates 100 clocks to each process in each iteration. Then, first P1 will be run for 100 clocks (0.0001 seconds), then P2(0.0001 seconds) followed by P3(0.0001 seconds), now since there are no more processes, this cycle repeats untill P2 ends and then followed by P3’s execution and eventually its termination.
This is a complete waste of the 100 CPU clock cycles. To avoid this, we mutually give up the CPU time slice, i.e. yield, which essentially ends this time slice and the scheduler picks up the next process to run. Now, we test our condition once, then we give up the CPU. Considering our test takes 25 clock cycles, we save 75% of our computation in a time slice. To put this graphically,
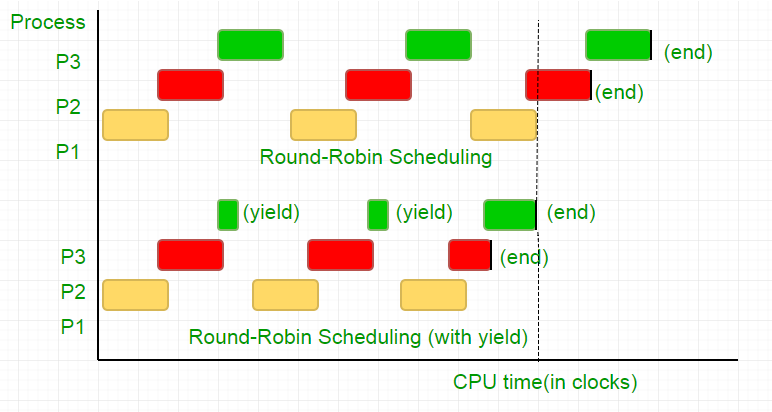
Considering the processor clock speed as 1MHz this is a lot of saving!.
Different distributions provide different function to achieve this functionality. Linux provides sched_yield().
Memory fence.
The code in earlier tutorial might have worked on most systems, but is was not 100% correct. The logic was perfect, but most modern CPUs employ performance optimizations that can result in out-of-order execution. This reordering of memory operations (loads and stores) normally goes unnoticed within a single thread of execution, but can cause unpredictable behaviour in concurrent programs.
Consider this example,
In the above example, the compiler considers the 2 statements as independent of each other and thus tries to increase the code efficiency by re-ordering them, which can lead to problems for concurrent programs. To avoid this we place a memory fence to give hint to the compiler about the possible relationship between the statements across the barrier.
So the order of statements,
flag[self] = 1;
turn = 1-self;
while (turn condition check)
yield();
has to be exactly the same in order for the lock to work, otherwise it will end up in a deadlock condition.
To ensure this, compilers provide a instruction that prevent ordering of statements across this barrier. In case of gcc, its __sync_synchronize().
So the modified code becomes,
Full Implementation in C:
Output:
Thread Entered: 1
Thread Entered: 0
Actual Count: 2000000000 | Expected Count: 2000000000
This article is contributed by *Pinkesh Badjatiya *. If you like GeeksforGeeks and would like to contribute, you can also write an article using contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
데커(dekker) 알고리즘
- 두 개의 프로세스를 위한 상호배제의 최초의 소프트웨어 해결법
- Boolean flag[2]와 int turn 의 공유변수를 가진다.
초기값은 flag[0] = flag[1] = false이고, turn = 0 또는 1의 값을 가진다. - Pi의 구조
- 임계영역에 들어가려면 flag[i] = true로 설정한 후, Pj가 임계영역에 들어가려 하거나 이미 임계영역에 있는지를 확인.
- Pj가 임계 구역에 있지 않고 들어가려 하지도 않으면(flag[j] = false), Pi가 임계영역으로 진입.
- 임계영역에서 나오는 Pi 프로세스는 빠져 나옴(flag[i] = false)을 알리고, turn은 기회를 양보하기 위해서 j로 함.
while(1){
...
flag[i] = true; //임계영역에 들어가려고 시도.
while(flag[j]){ // Pj가 임계영역에 있는지 조사
if(turn == j){ // Pj가 들어갈 기회라면
flag[i] = false; //일단 진입 취소
while(turn == j); //순서를 기다림
flag[i] = true;
}
}
//임계영역(Critical Section)
...
turn = j; // 진입 순서 양보
flag[i] = false; //임계영역 사용 완료 지정
}피터슨(Peterson) 알고리즘
- 프로세스들은 boolean flag[2], int turn의 공유 변수를 가짐
- 프로세스 Pi의 구조
- 임계영역에 진입하려면 먼저 flag[i] = true로 하여 임게영역에 들어가고 싶다는 의사 표시.
- turn=j로 설정한 후, 프로세스 j가 임계영역에 들어갈 의사가 없다면(flag[j] = false) 임계영역에 들어갈 수 있음
- 두 개의 프로세스가 동시에 임계영역에 진입하려고 한다면 turn변수가 늦게 수행된 프로세스가 기회를 양보.
- 임계영역에서 나오는 프로세스는 flag[i]를 false로 함으로써, 다른 프로세스가 임계영역에 들어가도록 허용.
while (1) {
...
flag[i] = true; // 임계영역에 들어가려고 시도
turn = j; // 상대방에 진입 기회 양보
while (flag[j] && turn == j); // 상대방이 진입하려고 한다면 대기
// 임계영역(critical section)
...
flag[i] = false; // 임계영역 사용 완료 지정
...
}Lamport의 제과점 알고리즘(bakery Algorithm)
- 분산처리 환경에 유용한 알고리즘
- 번호를 부여받고 낮은 번호가 먼저 온 것이므로 먼저 수행
- 프로세스들은 한계 대기 조건을 만족하면 되지, 반드시 들어온 순서대로 수행되어야 하는 것은 아니다.
- bool choosing[n]과 int number[n] 변수들을 사용
bool choosing[n]은 초기값으로 false가 설정되고 번호표를 받기 전에 true, 받은 후 false.
number[n]은 0으로 초기화(n 은 프로세스 수) - 프로세스 Pi 의 구조
while (1) {
...
choosing[i] = true; // 번호표 받을 준비
// 다음 번호를 생성하여 할당
number[i] = max(number[0], number[1], ...,number[n-1]) + 1;
choosing[i] = false; // 번호표를 받았음.
for (j = 0; j < n; j++) { //모든 프로세스에 대한 번호표 비교루프
while (choosing[j]); // 비교할 Pj가 번호표 받을 때까지 대기
while (number[j]&&(number[j], j)<(number[i], I));
// Pj가 번호표를 갖고 있고 Pj의 번호표가 Pi의 번호표보다
// 작거나 또는 번호표가 같을 경우 j가 i보다 작다면
// Pj의 종료(number[j]=0)까지 대기
}
// Critical Section
...
number[i] = 0; // 사용완료로 번호표 취소
...
}- Pi의 임계영역 진입조건은 모든 프로세스 j(0<=j<n)에 대한 검사를 종결한 시점 즉, 어떤 프로세스도 Pi의 번호표보다 작은 번호표를 갖고 있지 못한 상태이다.
- 이 알고리즘은 상호 배제, 한계 대기, 진행 조건을 모두 만족.
1. Bounded-Buffer Problem(Producer-Consumer Promblem)
여러 개의 프로세스를 어떻게 동기화할 것인가에 관한 고전적인 문제. 한정버퍼문제라고도 함.
문제 정의
유한한 개수의 물건(데이터)을 임시로 보관하는 보관함(버퍼)에 여러 명의 생산자들과 소비자들이 접근한다. 생산자는 물건이 하나 만들어지면 그 공간에 저장한다. 이때 저장할 공간이 없는 문제가 발생할 수 있다. 소비자는 물건이 필요할 때 보관함에서 물건을 하나 가져온다. 이 때는 소비할 물건이 없는 문제가 발생할 수있다.

1. 불완전한 방법 (resource count)
변수()
- Empty : 버퍼 내에 저장할 공간이 있는지를 나타낸다.(초기값은 n)
- Full : 버퍼 내에 소비할 아이템이 있는지를 나타낸다. (초기값은 0)
- Mutex : 버퍼에 대한 접근을 통제한다. (초기값은 1)
프로세스
생산자 프로세스
do{ ... 아이템을 생산한다. ... wait(empty); //버퍼에 빈 공간이 생길 때까지 기다린다. P(empty) wait(mutex); //임계 구역에 진입할 수 있을 때까지 기다린다.P(mutex) ... 아이템을 버퍼에 추가한다. ... signal(mutex); //임계 구역을 빠져나왔다고 알려준다. V(mutex) signal(full); //버퍼에 아이템이 있다고 알려준다. V(full) }while(1)소비자 프로세스
do{ wait(full); //버퍼에 아이템이 생길 때까지 기다린다. wait(mutex); ... 버퍼로부터 아이템을 가져온다. ... signal(mutex); signal(empty); //버퍼에 빈 공간이 생겼다고 알려준다. ... 아이템을 소비한다. ... }while (1)
2. 모니터를 이용한 방법(monitor)
monitor ProducerConsumer{
int itemCount = 0;
condition full;
condition empty;
procedure add(item){
if(itemCount == BUFFER_SIZE){
wait(full);
}
putItemIntoBuffer(item);
itemCount = itemCount + 1;
if(itemCount == 1){
notify(empty);
}
}
procedure remove(){
if(itemCount == 0){
wait(empty);
}
item = removeItemFromBuffer();
itemCount = itemCount - 1;
if(itemCount == BUFFER_SIZE - 1){
notify(full);
}
return item;
}
}
procedure producer()
{
while (true)
{
item = produceItem();
ProducerConsumer.add(item);
}
}
procedure consumer()
{
while (true)
{
item = ProducerConsumer.remove();
consumeItem(item);
}
}2. Readers-Writers problem
문제 정의
여러 명의 독자와 저자들이 하나의 저장 공간(버퍼)을 공유하며 이를 접근할 때 발생하는 문제이다. 독자는 공유 공간에서 데이터를 읽어온다. 여러 명의 독자가 동시에 데이터를 읽어오는 것이 가능하다. 저자는 공유 공간에 데이터를 쓴다. 한 저자가 공유 공간에 데이터를 쓰고 있는 동안에는 그 저자만 접근이 가능하며, 다른 독자들과 저자들은 접근할 수 없다.
마찬가지로 세마포어로 해결할 수 있다.
문제해결
방법
변수
- readcount : 현재 버퍼에 접근 중인 독자의 수를 나타낸다. (초기값 = 0)
- wrt : 저자들 사이의 관계를 통제한다. 즉, 동기화한다. (초기화 = 1)
- mutex : readcount와 wrt에 접근하는 것이 원자적으로 수행될 수 있도록 하는 세마포어 (초기값 = 1)
저자 프로세스
wait(wrt); // 임계구역에 들어가기 위해 허가가 나기를 기다린다. ... 쓰기 작업 수행 ... signal(wrt); // 임계구역에서 빠져나왔음을 알린다.독자 프로세스
wait(mutex); readcount++; // 독자수 1 증가 if(readcount == 1) wait(wrt); //쓰고 있는 저자가 없을 때까지 기다린다. signal(mutex); ... 읽기 작업 수행 ... wait(mutex); readcount--; // 독자 수 1 감소 if(readcount == 0) signal(wrt); //독자가 없다면 이를 알린다. signal(mutex);
##3. Dining-Philosophers Problem

식사하는 철학자문제는 동시성과 교착상태를 성명하는 예시.
문제정의
다섯 명의 철학자가 원탁에 앉아 있고, 각자의 앞에는 스파케티가 있고 양옆에 젓가락이 한 짝씩 있다. 그리고 각각의 철학자는 다른 철학자에게 말을 할 수 없다. 이때 철학자가 스파게티를 먹기 위해서는 양 옆의 젓가락짝을 동시에 들고 있어야 한다. 이때 각각의 철학자가 왼쪽의 젓가락 짝을 든 다음 오른쪽의 젓가락 짝을 들 때까지 무한정 기다리는 교착 상태에 빠지게 될 수 있다.
또한 어떤 경우에는 동시에 젓가락 양짝을 집을 수 없어 식사를 하지 못하는 기아 상태가 발생할 수도 있고, 몇몇 철학자가 다른 철학자보다 식사를 적게 하는 경우가 발생하기도 한다.
1. 왼쪽 포크가 사용 가능해질 때까지 생각을 한다. 만약 사용 가능해지면 집어든다.
2. 오른쪽 포크가 사용 가능해질 때까지 생각을 한다. 만약 사용 가능해지면 집어든다.
3. 양쪽의 포크를 잡으면 정해진 시간만큼 식사를 한다.
4. 오른쪽 포크를 내려놓는다.
5. 왼쪽 포크를 내려놓는다.
6. 다시 1번으로 돌아간다.해결책
OS차원의 해결법.
한 철학자가 포크를 잡는다면, 반대쪽 포크를 잡을 때까지 행동권을 넘길 수 없게하는 것이다. 현실 세계에서는 CPU의 인터럽트를 무시하는 방식(선점적 멀티태스킹의 Context Switching은 대게 타이머 인터럽트에 의해 발생한다.)으로 구현할 수 있다. 하지만 이는 커널 레벨에서만 가능한 방식으로, 사용자에게 인터럽트 제어권을 넘겨준다면 악의적으로 사용해 혼자 CPU를 소비하는 상황이 발생할 수 있다.
단 멀티쓰레드 환경이라면 사용자 레벨에서 구현할 수 있는 방식이 있다. 사용자가 Semaphore나 Mutex lock등을 이용해 Critical Section(공유 자원에 Write를 수행하는 경우 등)에서 자신이 만든 다른 쓰레드가 CPU를 잡지 못하게 만들어 쓰레드간의 교착 상태를 방지할 수 있다.
하드웨어 아키텍처 차원의 해결법.
CPU에서 제공하는 명령어를 이용할 수도 있다. 양쪽 포크를 동시에 잡게 하는 명령어를 사용하면 두 철학자가 동시에 하나의 포크만 잡는 상황은 벌어지지 않는다. 쪼갤 수 없는 명령어라는 의미로 Atomic Instruction이라고도 한다.
소프트웨어 차원의 해결법.
철학자들 중 하나는 포크를 오른쪽부터 잡게 한다고 생각해 보자. 예를 들어 1번 철학자는 왼쪽부터, 2번 철학자는 오른쪽부터 잡는다. 1번 철학자가 왼쪽 포크만 잡은 상태에서 행동권이 2번 철학자에게 넘어간다고 하더라도, 2번 철학자는 자신의 오른쪽 포크가 현재 사용 불가능하기 때문에, 첫번째 포크를 잡으려는 상황에서 멈춰 있게 된다. 이 상황에서 1번 철학자로 다시 행동권이 넘어오게 되면 1번 철학자는 자신의 오른쪽 포크를 잡고 다시 식사를 할 수 있게 된다.
DeadLock
조건.
- 상호배제
- 비선점
- 보유 대기
- 순환대기
처리 방법.
예방은 위 4가지 중 어느 하나가 만족되지 않도록 하는 것
데드락 Avoidance
두 가지 알고리즘이 존재함.- Single instance per resource types
- Resource Allocation Graph algorithm 사용- Multiple instance per resource types
- Banker's Algorithm 사용
Avoidance
Resource Allocation Graph algorithm
- Resource Allocation Graph를 사용해 Process의 수행 순서를 결정함.
- 미래에 사용할 자원을 나타내는 Claim Edge를 사용한다.(점선)
=> 요청할 때 점선이 실선으로 바뀜, 이 때 cycle이 생기지 않으면 자원을 할당함.

- 위와 같은 상황에서 P2가 R2를 요청해 할당받게 되면 Cycle이 생기게 된다. 이러한 경우 Resource를 할당받지 않고 P1이 끝나기를 기다린다.
Banker's Algorithm
- Multiple instances (Banker's Algorithm)
- 가진 자원 정보를 가지고 safe state가 존재하는지 확인하고 하나의 경우라도 존재하는지 확인하여 deadlock을 회피할 수 있는 알고리즘
- 프로세스가 사용할 자원들을 미리 보고 Safe sequence를 찾는 알고리즘이다.
데드락을 피하기 위해 어떤 프로세스를 먼저 종료할 것인가?
Dectection
- Detection은 Prevention과 거의 같은 방식을 이용한다.
- Detection도 single Instance와 Multiple instance로 나누어지는데 single instace는 회피와 마찬가지로 RAG 활용
- Multiple instace일 경우, banker's Alogirithm과 유사하지만 need가 아니아 request 사용.
Recovery
- Deadlock이 발생한 상황에서 복구하는 방법
1) Process Termination
- Deadlock이 일어난 모든 프로세스를 종료시키는 방법
- 하나의 프로세스씩 종료시키며 deadlock cycle이 없어질때까지 반복한다.
2) Check&Rollback
- 비용을 최소화할 victim process를 선정한다.
- safe state로 return하고 프로세스를 재시작한다.
Ignorance
- Deadlock이 일어나지 않는다고 생각하고 아무런 조치도 취하지 않음.
LRU / LFU 구현
Clock Algorithm
'CS > 운영체제' 카테고리의 다른 글
| 06. Process Synchronization (0) | 2019.07.28 |
|---|---|
| 05. CPU Scheduling-01 (0) | 2019.07.28 |
| 04. Process Management (0) | 2019.07.28 |
| 02.Process (0) | 2019.07.28 |
| 01.컴퓨터 구조와 프로그램 실행 (0) | 2019.07.28 |




댓글