추가) 관련 IDGenerator 오픈소스을 만들었습니다. ( github link )
배경
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
}위 코드는 어떤 코드인지 짐작이 가는가?
JPA 을 학습한 사람이라면 한번에 인지했을 것이다. 데이터베이스에 어떤 데이터을 저장시키기 위해서 데이터베이스에게 오름차순의 숫자을 요청하여 식별자 을 생성해내는 코드이다. 포스팅 제목에서 보았던 IDGenerator 종류의 하나이다. 이 쯤에서 제목에서 말하는 IDGenerator 는 무엇인지 이해할 필요가 있다.
앞에서 이미 언급된 '식별자' 을 만들어 주는 것이 IDGenerator 의 역할이다.
'식별자' 의 의미는 무엇일까? 도메인주도설계에서 식별자는 엔티티을 구별할 수 있으며, 추적 가능하도록 만들어 주는 것이라 말한다.
IDGenerator 종류는 또 무엇이 있을까?
UUID(Universally Unique IDentifier)
대표적으로 말할 수 있는 다른 종류로는 UUID 가 있다. 128 Bit 데이터로 표현되는 UUID 는 분산 시스템 상에서 어떤 곳에서 통제하지 않아도 유일성을 가진 식별자을 만드는 것을 목표로 한다.
목표을 달성하기 위해 트레이드-오프된 부분으로는 거대한 용량(128Bit)일 것이다.
서드파트 어플리케이션(third party Application)
1. Flickr의 Ticket Server
https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
Ticket Servers: Distributed Unique Primary Keys on the Cheap | code.flickr.com
This is the first post in the Using, Abusing and Scaling MySQL at Flickr series. Ticket servers aren’t inherently interesting, but they’re an important building block at Flickr. They are core to topics we’ll be talking about later, like sharding and
code.flickr.net
아주 심플한 방법으로 ID 을 생성해주는 도구이다.
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1
TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2데이터베이스의 nextVal() 을 요청할 수 있는 2개의 서버을 만들고, 하나는 1,3,5... 다른 하나는 2,4,6... 의 형태로 ID 을 발급받아 사용하는 방법이다.
아래 설명할 Snowflake 와 많이 비교하는 경우가 많고, 그 이유는 snowflake 에 비해서 멍청하지만 잘 동작되기 때문이다. 아래 Snowflake 에 대한 설명을 읽고나서 조금 더 이해가 쉬워지지 않을까?
2. Twitter 의 Snowflake
https://darkstart.tistory.com/147
[서버]Distributed System Twitter id 생성(Snowflake)
트위터에 이런 좋은 자료도 있군요. 무려 10년 전의 자료입니다. 너무 길어서.. 그냥 구글 번역기에서 돌린 번역 내용과 원본 내용을 같이 붙입니다. 일반적으로 MySQL에서 id를 보면 unsigned 32bit라
darkstart.tistory.com
snowflake 는 시간 기반의 ID 을 생성해주는 도구이다.

ID의 형태는 다음과 위와 같습니다.
64 bit 의 숫자안에 41bit 는 시간 기반의 값을. 10bit 는 machine id 을 그리고 마지막 12 bit 는 단순히 sequence 을 보장하도록 한다.
서비스에 맞쳐서 ID 의 크기을 자유자재로 변경할 수 있으며, 가장 큰 특징은 ID 을 거친 정렬할 수 있다는 것이다.
(실제로 snowflake 방식은 IdGenerator 서버을 필자가 근무하는 회사에서도 동작되는 소프트웨어로 사용중이다. 개인적으로 효율적인 도구라 생각한다.)
우리는 약 4개의 IDGenerator 을 알아보았다.
이번에는 4개의 IDGenerator 가 언제 ID 을 생성해주는지 알아보자.
ID가 생성되는 시점은 언제일까? 순서가 중요할 수 있다.
빠른 식별자 생성과 할당은 엔티티가 저장되기 전에 일어난다.
늦은 식별자 생성과 할당은 엔티티가 저장될 때 일어난다.
먼저, 결론부터 이야기하면 두 방식 모두 정답이 맞을 수도 있고, 아닐수도 있다. 서비스에 따라 다를 것이다.
우리가 흔히 사용하는 @GeneratedValue(strategy = GenerationType.AUTO) 가 늦은 생성자의 대표적인 부분이다. 늦은 생성자는 무엇이 문제가 될까?
코드 상에서 아직 식별자을 할당받지 않은 객체가 Set 안에 2개 이상 포함되어 있다면, 어떻게 식별할 것인가? 늦은 생성자는 DB 의 의존성을 갖기 때문에 무엇인가 행동하기 위해서는 DB에게 '나의 식별자을 알려줘!' 라고 물어야만 할 것이다.

빠른 식별자는 어떠할까? 빠른 식별자는 영속성 계층으로 들어가기 전 이미 식별자가 할당되어진 상태을 말한다. 이 방식은 언제 어떻게 ID 을 부여해야하는지에 대한 고민이 될 것이다. 즉 배보다 배꼽이 큰 상황을 야기할 수 있다.
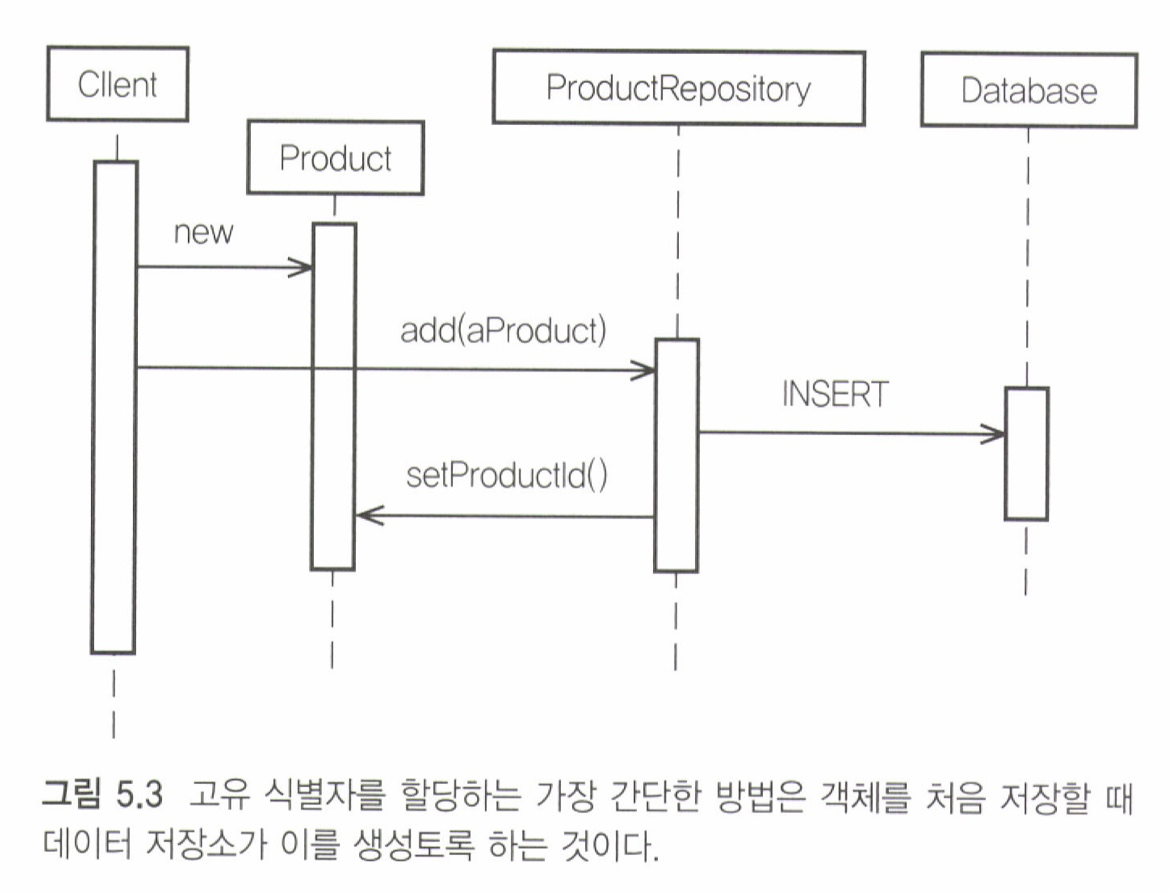
도메인주도설계(반버논)에서는 이 두가지에 대한 차이점을 도메인 이벤트을 활용해 비교한다. 늦은 생성자의 경우에는 도메인 이벤트을 발행하기 위해서 오직 데이터베이스에 저장된 후에만 사용될 수 있다. 그러므로 늦은 생성자은 식별자가 생성되기 까지 지연됨으로써 발생될 수 있는 문제점이 있음을 말하고 있다.
DB AutoIncrement 가 아니라, 왜 굳이 IDGenerator Server 을 만들었을까?
내가 트레바리 와서 가장 먼저 만든 것이 IDGenerator Server 였다. 이것이 왜 필요한가? 에 대해서 처음에는 겉으로 멋져보여서 좋았었다. 그렇게 1년이 지나고 IDGenerator 을 spring-autoconfiguration-starter 으로 만들면서 이런 질문에 대한 나의 생각을 다시 생각해 봤다. 'DB AutoIncrement 가 아니라, 왜 굳이 IDGenerator Server 을 만들었을까?'
가장 먼저 떠올랐던 정답은 DB 레턴시가 줄어 든다.인다. 이 또한 과거에 테스트을 해본 적이 있다.(github) 100000개의 ID을 만드는데, IDGenerator Server가 DB autoincrement 보다는 약 30배정도가 빨랐다. 그 외에 또 어떤 이유가 있을까?
트레바리는 snowflake 기반으로 IDGenerator Server 을 만들었는데, 식별자에 의미을 부여할 수 있게 된다. 언제 어디서 만들어졌는지 말이다. 우리가 아는 식별자는 흔히 DB에서 만들어 준 1,2,3 이런 종류인데(도메인 주도 설계에서는 이것을 대리키라 부른다) 반해, IDGenerator Server는 식별자에 우리가 계약한 의미을 창조해낼 수 있다. (이것의 의미는 도메인주도설계에서는 애그리거트 당 식별자을 할당할 수 있다는 의미와 가깝다.)
마지막으로, 분산환경에서의 unique ID 을 만들어 낼 수 있다는 것이다. snowflake idgenerator 블로그에서도 찾아볼 수 있는데, 이것을 만든 계기 자체가 분산 환경에서 사용하기 위한 용도로 만들어진 것이다. 작은 데이터에서는 효용을 느끼기 어려울 수 있지만 큰 데이터에서는 분명 엄청 큰 격차을 느낄 수 있다고 생각한다.
너무 좋은 이야기만 한 것 같아, 마치 약을 팔고 있는 느낌이다. 제목에서 말했다시피, 굳이 라는 용어에 집중해보면 단점은 다음과 같다.
IDGenerator Server는 관리해야될 요소로 자리잡는다. 관리해야될 요소라는 건 인프라 안에 있는 것이고, 이것은 단일실패지점이 될 수도 있다는 이야기이다. 또한 작은 프로젝트에서는 배보다 배꼽이 더 큰 내용이 될 수 있으며- 불필요한 오버엔지니어링을 남용하기가 너무나도 쉽다.
'가치관 쌓기 > 개발 돌아보기' 카테고리의 다른 글
| 개발DB 꼭 필요한가요? 진짜 필요한거예요? (0) | 2023.02.24 |
|---|---|
| 왜 테스트 코드를 작성하는 걸까? (0) | 2022.10.29 |
| Mockito을 왜 쓰는지 모르겠다? (with. Test Double) (0) | 2022.09.22 |
| 좋은 테스트에 대해서 이야기 하기 (0) | 2022.09.18 |
| 엄청 많은 속성을 가진 객체를 테스트해야 한다면 어떻게 해야될까?(with. test Data Builder) (0) | 2022.09.09 |



댓글