소프트웨어는 도메인에 관련된 문제를 해결하는 것에 초점이 맞춰져 있다.

함께 개발하는 것.
원칙적으로는 그렇다.

도메인 주도 설계의 맥락에서 도메인 모델 = 코드
해결해야할 두 가지 연관된 문제
요구사항에 적합한 모습으로 도메인을 어떻게 모델링할 것인가?
도메인을 반영한 코드를 어떻게 개발할 것인가?

= 올바른 모델이 찾는 것이 아니라, 유용한(수정하기 좋은/변경하기 좋은/코드짜기 좋은) 모델을 찾아야 한다.

DDD 는 위 두가지를 계속 이야기한다.

- 도메인을 잘 분석하면 코드로 연결해주는 것을 도와주는 부분이 파트 2에서의 내용

도메인을 분석해서 넣는게 좋은 블록들이
ASSOCIATION / VALUE OBJECT / ENTITY / SERVICE / MODULE
이렇게 해놓고 실제로 동작하는 기능을 만들어야 하는데, 예를들어 저장/생성은
AGGREGATE / REPOSITORY / FACTORY

{kind=link}

파트 2에서는 도메인의 개념을 코드로 옮기기 위한 직관적이고 쉬운 가이드.
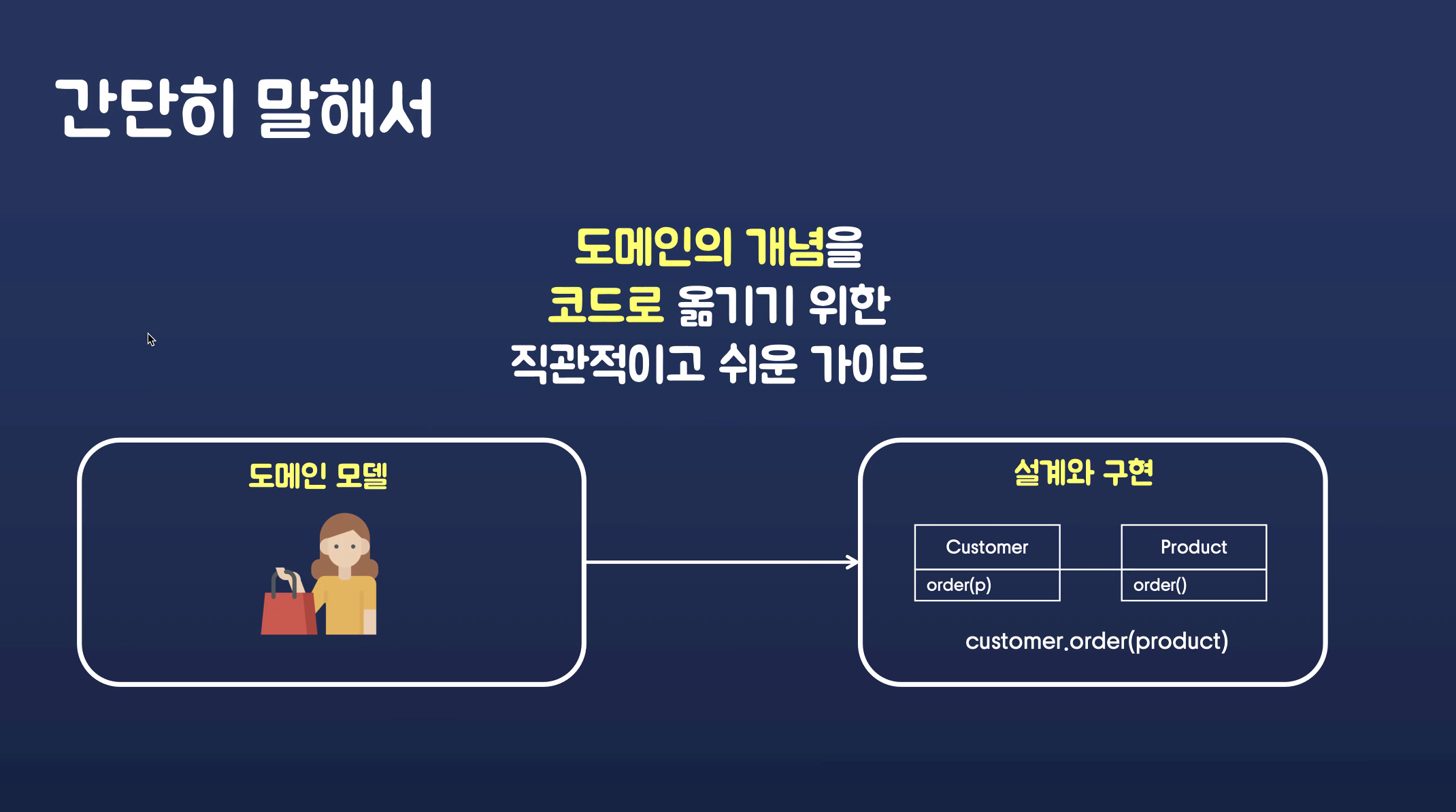
"~~ 이렇게 하면 복잡성을 낮출 수 있어요" 라는 것을 설명하는게 파트2

엔티티와 값 객체
엔티티/값객체 에 집착하는 경향이 있다.
본질적으로 이건 엔티티이고 값객체이다 라고 하는 것이 없다. 코드를 잘 짜게하는 방법을 찾는 그 어떤 개념이라면 다 맞다.
엔티티
수많은 객체는 본질적으로 해당 객체의 속성이 아닌 "연속성"과 "식별성"이 이어지는지 를 기준으로 정의된다.
값객체
개념적 식별성이 없는 객체 도 많은데, 이러한 객체는 사물의 어떤 특성을 묘사한다.

시스템에서 해당 객체를 어떻게 사용하냐에 따라 엔티티가 될 수도 있고 값객체가 될 수 있다.
연속성과 식별성 - 엔티티
어떤 객체를 일차적으로 해당 객체의 식별성으로 정의할 경우 그 객체를 ENTITY라 한다.
ENTITY에는 모델링의 설계상의 특수한 고려사항에 포함돼 있다. ENTITY는 자신의 생명주기 동안 형태의 내용이 급격하게 바뀔 수도 있지만 연속성은 유지해야 한다.
형태가 다르더라도, 추적할 수 있어야 한다.
어떤 객체를 일차적으로 해당 객체의 식별성으로 정의할 경우 그 객체를 ENTITY라 한다. ENTITY에는 모델링의 설계상의 특수한 고려사항에 포함돼 있다. ENTITY는 자신의 생명주기 동안 형태의 내용이 급격하게 바뀔 수도 있지만 연속성은 유지 해야 한다.
엔티티를 사용하면 복잡도가 높아진다.
값 객체
ENTITY의 식별성을 관리하는 일은 매우 중요하지만 그 밖의 객체에 식별성을 추가 한다면 시스템의 성능이 저하되고, 추가적인 분석작업이 필요하며, 모든 객체를 동 일하게 보이게 해서 모델이 혼란스러워질 수 있다. 소프트웨어 설계는 복잡성과의 끊임없는 전투다. 그러므로 우리는 특별하게 다뤄야 할 부분과 그렇지 않은 부분을 구분해야 한다.

딱 떨어지는 것이 아니라 구현과정에서 값 객체와 엔티티가 변경될 수 있다.

Value Object 는 왜 불변객체여야 하는가?
= 휠씬 쉽다.

필요한 정보를 얻기 위해서는 그냥 가면 된다.
가급적이면 Value Object 로 만드는 것이 DDD의 이론 중 하나.
- 표현을 좋게 하기 위한 방법으로 ValueObject 사용
- 중복코드를 뜯어내고 싶다면 ValueObject 로 만든다.

'만들면서 가변객체로 하면 불편하니까 불변객체로 만들자'가 된다.
ValueObject 를 가진 Entity 가 있다면
엔티티 하나와 나머지는 VO로 구성된 것이 애그리게이트이다.

엔티티는 복잡도를 끌고 갈 수밖에 없다. VO로 바꿀 수 밖에 없으면 바뀌야 한다.
어떻게 쓸것인가에 따라, Entity와 ValueObject가 달라진다.

예를 들어 복잡할 경우, 엔티티를 간단하게 짜는게 중요하다.

클래스를 3개로 쪼갠다. 사용하는 것이 동일하다면. 그것이 ValueObject가 된다.
어떻게?? 아래와같이 한다.

코드를 편하게 짜기 위해서 엔티티/값객체를 사용한다. 이게 중요하다.

돈이라고 하면 대부분 ValueObject를 떠올리지만 도메인에 따라/경우에 따라 Entity가 될 수도 있고 ValueObject가 될 수 있다.
연관관계, 애그리게이트, 리파지토리


애그리게이트를 이해하려면 연관관계에 대해서 이해해야 한다.

최대한 단순화하게 해야한다.

1.탐색 방향 부여하기
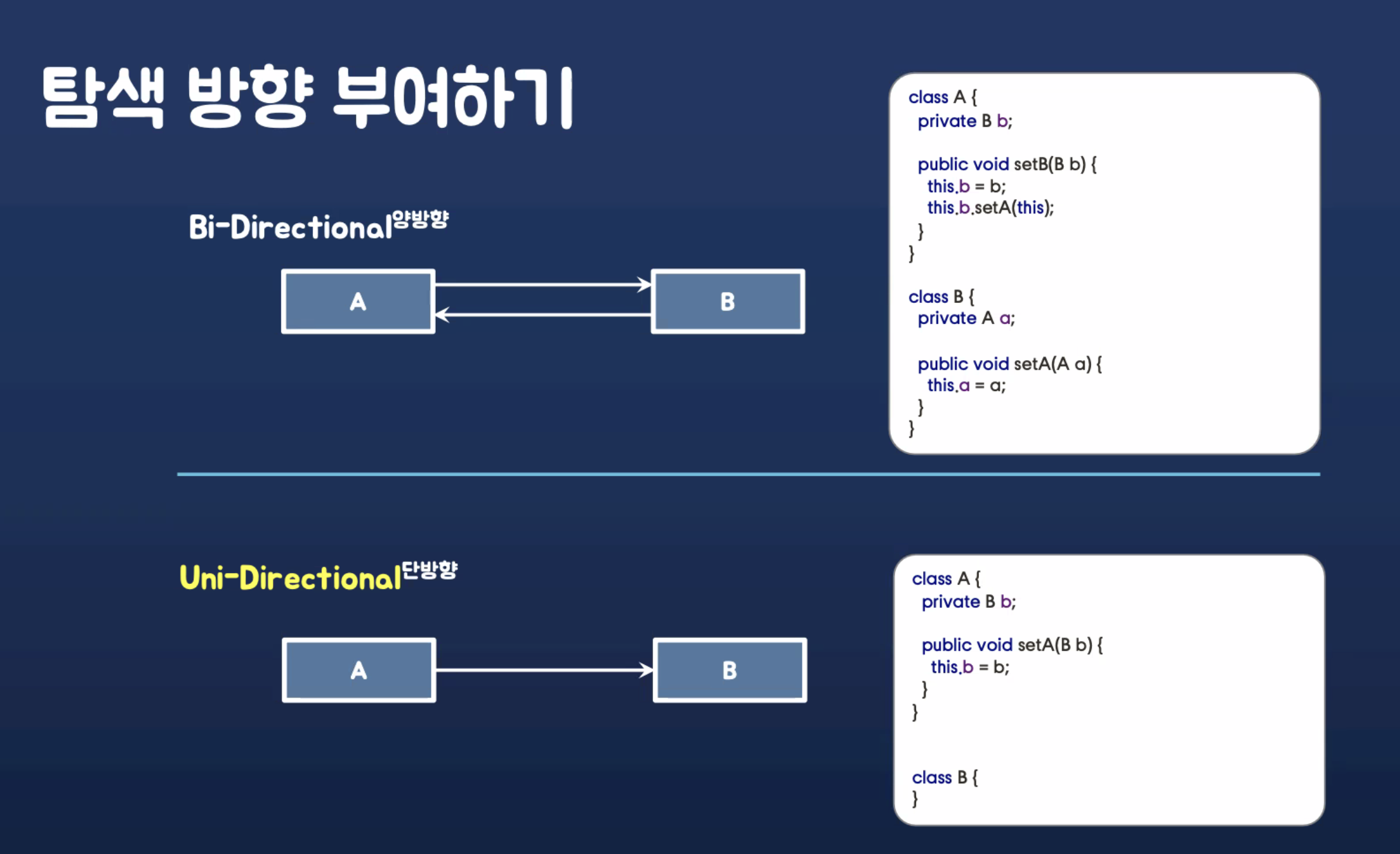
- 양방향은 복잡해서 어렵다. DB는 양방향이 있지만 객체는 양방향이 없다.

일대다 보다는, 다대일을 관리하는게 편하다.
꼭 그런건 아니지만 필요없으면 날려라!

연관관계와 탐색가능성

Order가 뭔지 알면 Order를 통해 원하는 Shop을 찾을 수 있다. "개념적으로"
- 객체 참조를 통한 탐색 - 강한 결합도

- 제3의 객체를 통한 탐색 - 약한 결합도



불변식이 왜 중요할까?
주문이 있고, 고객이 있는데-

애그리게이트가 왜 나왔냐? 불변식이 틀어지면서 발생했다.


문제의 원인은 아무 객체나 접근해서 수정하거나 삭제가 가능하면서 발생한다.
불변식이 여러 애그리게이트를 합쳐서 확인해야 한다.

애그리게이트는 객체들을 그룹으로 묶어 내부에 직접 접근할 수 없도록 캡슐화.
애그리게이트는 불변식을 떠올리는 것이 좋다.

밖에서는 루트만 참조할 수 있게 한다.
일단 경계를 묶어 버린다.

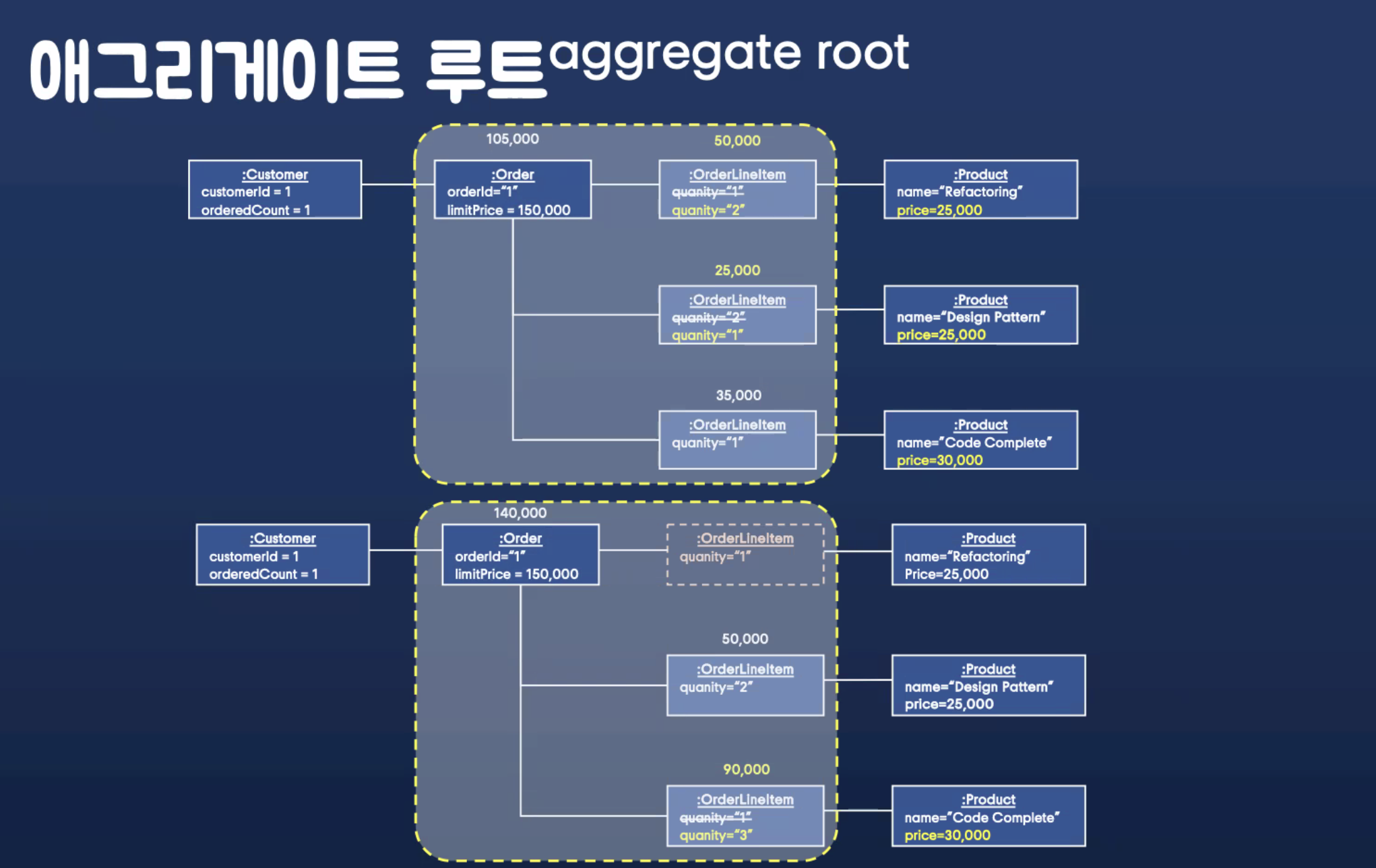
외부의 애그리게이트 루트만 접근 가능

도메인을 잘 분석해야만 애그리게이트를 잘 만들 수 있다.

리포지토리 팩토리는 애그리게이트에서 파생된다.
불변식의 단위를 애그리게이트라고 한다.
불변식을 기준 으로 애그리게이트 경계 정의

비즈니스를 잘분석하면 애그리게이트가 나오고 그 다음 트랜잭션으로 묶어. 그럼 단순해질거야! 라고 하는 것이 책에서 말하는 내용이다.
애그리게이트는 데이터 저장/조회의 단위가 될 것이다.

Eager 로딩을 쓴다. Lazy 로딩을 잘 안쓴다.

우리는 연관 관계를 통해 다른 객체와의 관계에 근거하여 특정 객체를 찾을 수 있다. 그러나 객체의 생명주기 중간에도 ENTITY나 VALUE를 탐색하기 위한 진입점이 있어야 한다.



객체를 찾아오거나, 객체를 통해서 찾아거나 2가지 방법이 있다.

객체를 써야해? Id 를 써야 해?


사용하는 객체에 따라 다르게 쓰여야 한다. 그러나 편안하게 쓰이기 위해서는 ID를 이용한 참조한다.



- 애그리게이트 내에서는 결합도가 높아도 된다.
- 애그리게이트 내에서는 양방향도 문제가 없다.


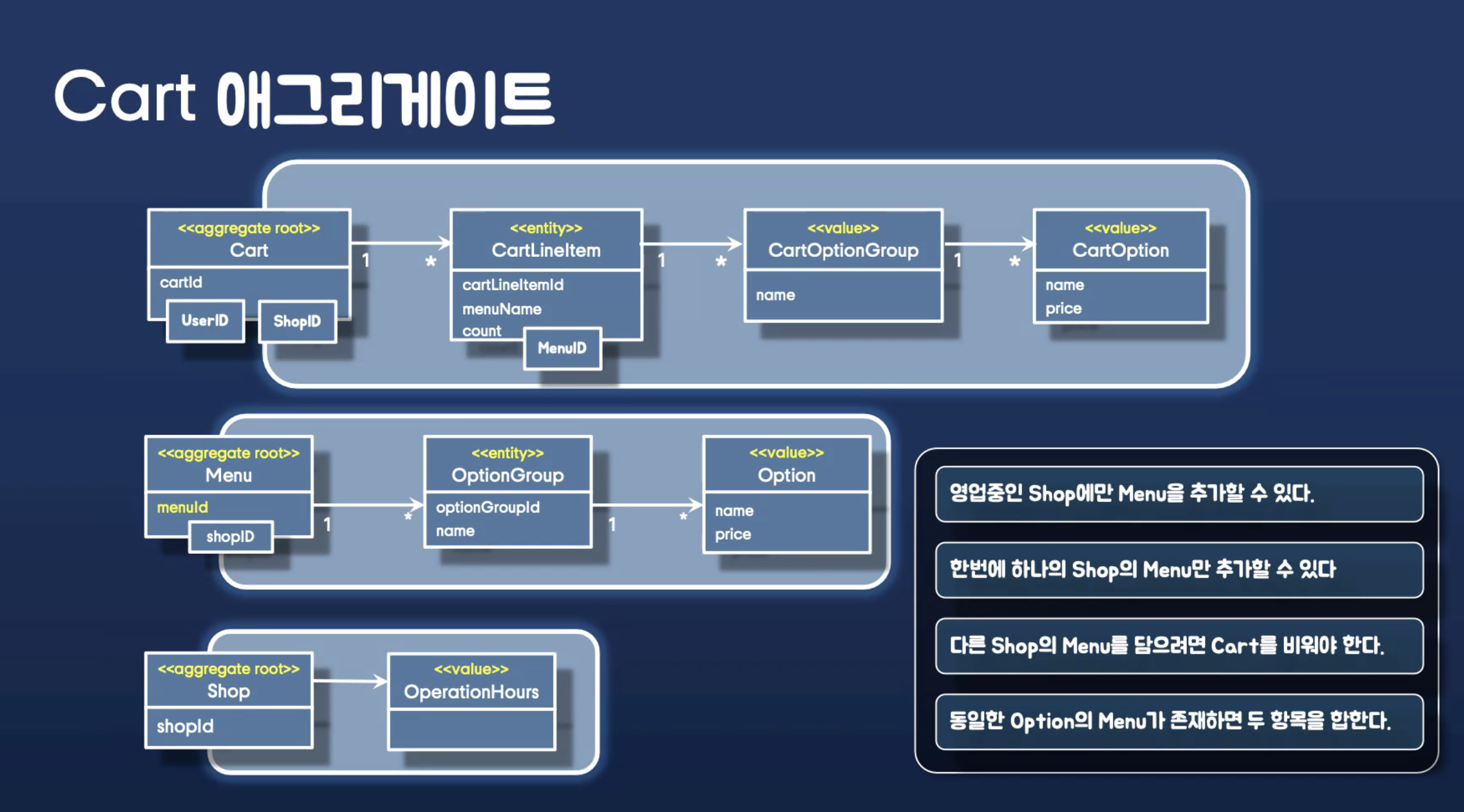
애그리게이트 예제
eternity-object/food-delivery

애그리게이트 경계를 잡는게 중요하다. 불변식을 하다보면서 나온다. 개발하면서 편한 단위. 너무 크지 않게. 이게 너무 MSA 관점으로 분리해야 한다 라고 이야기해서 이질감이 느껴지지만 그렇지 않다.


"나중에 이것만 수정하면 되겠구나?" 라는 것을 쉽게 하기 위해서.
애그리게이트 경계에 대해서 예시를 설명한다.


비지니스 로직은 Menu 에 다 들어간다. 그러니까 VO를 만들어 로직을 위임한다. 최대한 Menu 를 심플하게 만들기 위해서.


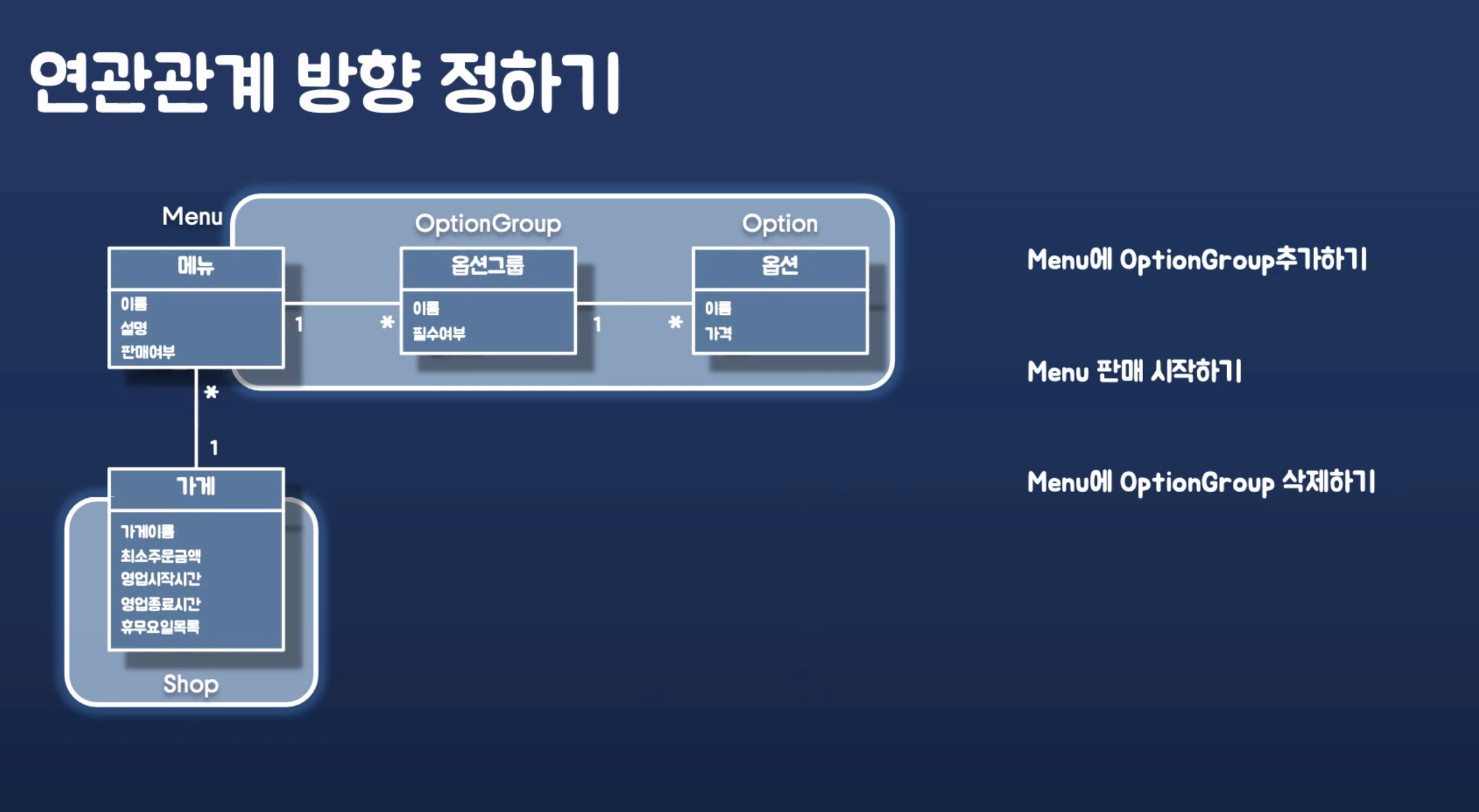


메뉴와 가게에서 N:1 이 복잡성을 더 감소시키므로 메뉴가 가게를 알도록 한다.

ValueObject 를 다 날리고 다시 밀어넣어. 그게 바로 ValueObject. ElementCollection 에서 그렇게 동작한다.

팩토리, 서비스
팩토리는 애그리게이트를 만드는 것.
주문하기 = Order 생성하기



Cart 에다가 Factory 를 넣어서 Order 를 만든다. 이렇게 할 경우 단점은


팩토리를 만드는 것또한 Aggregate 를 생성하는데, 의존성을 분산시키기 위해서.

서비스 3종류
- ApplicationService
- 어떤 Flow
- InfrastruchtreService
- DomainService
- 도메인 간에 애매한 부분
- 그러나 가급적 사용하지 않고, 도메인 객체를 만들려고 한다.

이렇게 쓰는게 맞는것같기도하고, 문제같기도하고~

도메인 로직만 분리하세요!
도메인 서비스에 대한 예시를 들어보면

애매할 때는 도메인서비스를 뽑아낸다.




DDD 는 비지니스 로직.
비지니스 로직은 뭔가를 수정하는 것
뭔가 상태가 바꿔야 한다. 읽기랑은 무관하다.
응집도가 떨어진다. 불필요한 쿼리. 성능에 대해서 신경을 썼지만. 이제는 그런 시대가 아니다.
사람과 기계값을 비교해보자. 그래서 MSA 가 되게 비효율적이지만 하드웨어적으로 수준이 많이 올라왔다.
댓글